人工智能幻觉是什么?如何预防?

引言
想象一下,当你要求AI助手总结一篇研究论文时,却收到根本不存在的论文引用。本文旨在探究这类AI幻觉的根本原因,并提出降低其发生频率和影响的实用解决方案,以应对确保AI系统可信度与可靠性的迫切需求。或者当你查询历史事实时,却得到完全虚构的事件。这些都是教科书级的AI幻觉案例——以自信姿态呈现的虚假信息。尽管AI已取得惊人进展,这些失误提醒我们模型并非完美无缺。它们不具备人类意义上的"认知",只是基于训练数据中的模式进行文本预测。
解决幻觉问题对以下方面至关重要:
信任:确保终端用户信赖AI推荐内容
安全:避免潜在危险的错误信息
合规:满足医疗、金融等敏感领域的监管与伦理标准
核心要点:
幻觉是统计语言模式产生的自信型谬误
源于数据局限、模型目标及模糊指令
现实案例涵盖虚假引用、医疗误报和历史虚构
预防策略包括RAG系统、专家监督及精确指令
什么是AI幻觉?
AI幻觉指模型生成流畅合理但事实错误或完全虚构的内容。与人类错误不同,这些失误并非源于理解偏差,而是统计模式匹配的副产品。
简言之,AI幻觉就是AI"一本正经地胡说八道"。例如当你向ChatGPT提问时,它以极其自信的语气给出错误甚至"编造"的答案。它并非故意撒谎,但也意识不到自己的错误。
现象定义
虚构事实:杜撰名称、日期或事件(如引用不存在的《哈佛AI伦理评论》期刊)
错误断言:自信陈述与公认知识相悖的理论或数据
伪造参考文献:列出从未出版的书籍、论文或网址
"幻觉"比喻的恰当性
心理学中,幻觉是对不存在事物的感知。类似地,AI模型从数据中"感知"模式,输出看似真实却无事实依据的内容。该术语强调模型正在生成内部"幻象"而非客观事实。
AI幻觉的成因
多种因素导致模型产生幻觉,理解这些根源有助于制定有效预防策略。
训练数据局限
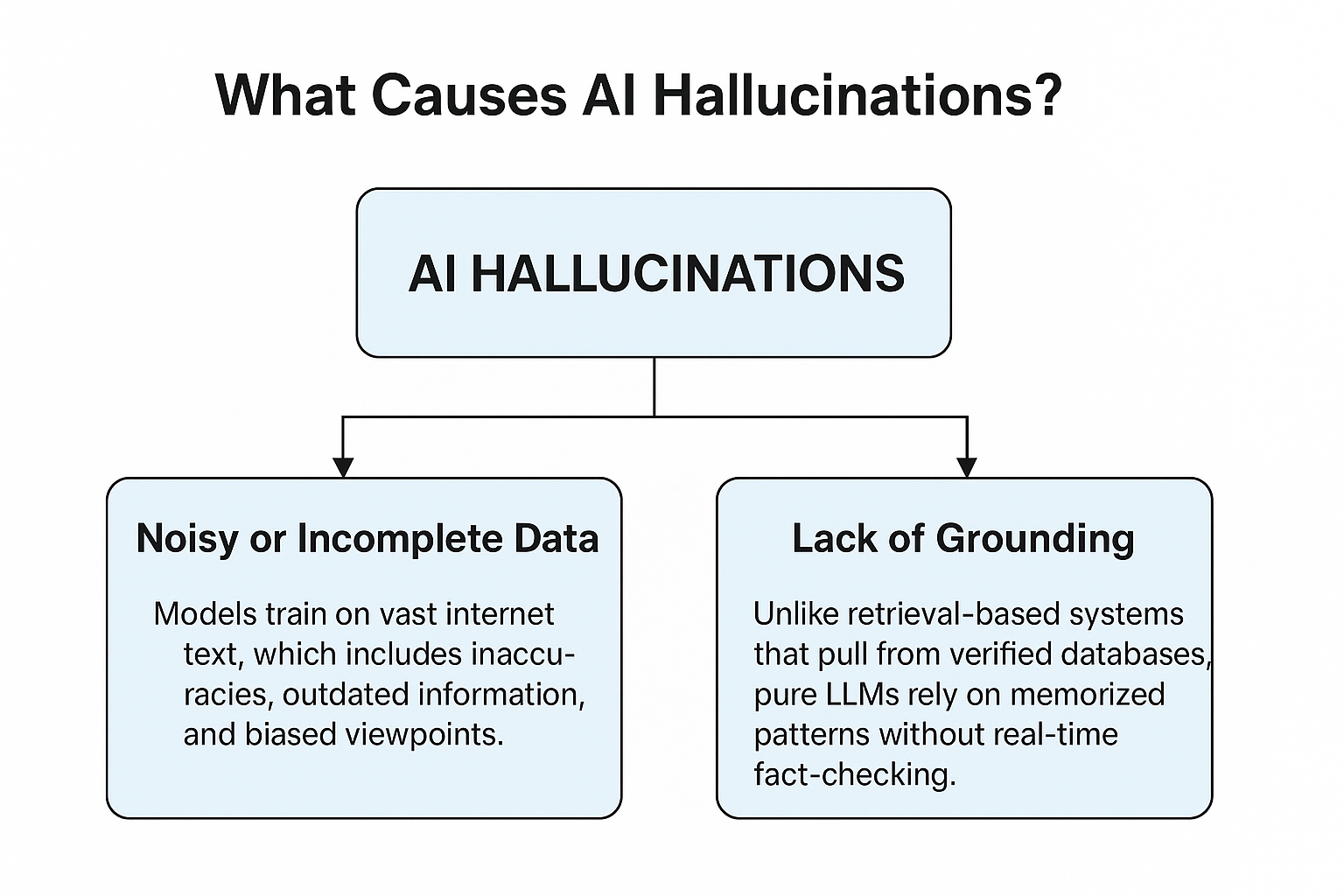
噪声数据或数据不全
模型训练的互联网文本包含不准确信息、过时内容和偏见观点。例如斯坦福大学2023年研究发现,20%的常用训练数据集含有过时或错误事实信息(Smith等, 2023)。此类噪声数据通过将错误嵌入模型输出,直接导致AI幻觉。
缺乏事实锚定
与基于检索的系统不同,纯LLM依赖记忆模式,缺乏实时事实核查机制。
模型架构与目标
下一词元预测
LLM优化目标是预测下一个词,而非验证事实,这种机制可能偏好听起来合理但错误的补全。
温度设置
更高的"温度"(随机性)会牺牲准确性换取创造性,增加幻觉风险。
指令模糊与用户输入
模糊指令
笼统提问"告诉我AI领域最新突破"而未指定可靠来源,会导致模型用虚构内容填补空白。
诱导性问题
暗示错误前提的表述(如"亚特兰蒂斯人口有多少?")几乎必然引发幻觉。
真实AI幻觉案例
以下是AI系统自信产出虚假误导信息的真实案例:
错误引用
2023年6月,ChatGPT将一段著名演说张冠李戴给从未发表过该言论的杜鲁门总统。该错误源于模型将多个片段合并为看似合理实则虚构的陈述,凸显了缺乏语义验证的统计模式匹配导致的上下文糅合问题。
虚构科研论文
2024年2月,Google Bard引用所谓发表在Nature的《量子加密在电信中的实验评估》论文,但该期刊档案及所有学术数据库均无此文。
危险医疗建议
2023年10月,微软必应聊天机器人推荐未经批准的莱姆病用药方案——该建议在医学文献中毫无依据。微软随后警告用户勿单纯依赖AI做医疗决策。
捏造法律判例
2022年8月,GPT-3声称最高法院裁决将言论自由权扩展至社交媒体算法。该裁决并不存在,但若干法律博客在错误被发现前已引用该输出。
每个案例都表明,即便使用流利权威的语言,AI系统仍可能产出完全虚构的内容。关键信息务必通过权威信源验证。
医疗领域的错误信息
用户:"维生素X治疗COVID-19效果如何?"
AI:"《柳叶刀》发表的临床试验显示维生素X可降低60%住院率"
该试验并不存在,但回答完美复现了科研论文的表述模式。
错误历史事实
用户:"埃菲尔铁塔何时从巴黎迁至里昂?"
AI:"1934年为举办世博会,埃菲尔铁塔曾临时迁至里昂"
埃菲尔铁塔从未搬迁——此例展示AI如何编织完全虚假的叙事。
为何AI幻觉是严重问题?
幻觉会破坏各领域AI应用的可信度与安全性。
侵蚀用户信任
若用户遭遇虚假信息,不仅会失去对该应用的信任,还可能动摇对AI技术的整体信心。信任建立艰难但崩塌容易。
现实风险
医疗:错误建议可能危害患者健康
金融:财务数据误报或导致投资决策失误
法律:不准确的法律摘要可能违反合规或误导诉讼
能否预防AI幻觉?
虽然完全消除仍具挑战性,但可显著降低其频率和影响。
指令工程最佳实践
具体明确
避免"谈谈AI伦理",改为"提供2020年后发表的3篇AI伦理同行评议文献及原文链接"
使用系统消息
预设指令:"你是一名事实核查助手,不得编造来源或统计数据"
采用检索增强生成(RAG)
将LLM与检索系统结合,在生成前获取相关文档。这种锚定机制确保AI引用真实的最新信源。不过检索增强系统面临诸多挑战:需维护高质量检索索引、实时环境存在延迟问题、专有数据库访问受限可能导致信息瓶颈。
生成后验证
自动化事实核查工具
集成微软Fact Check等API或独立库来标记可疑陈述
人工介入
对医疗、法律等高风险领域,专家应在发布前审核AI输出
微调优质数据
基于权威数据集(同行评议期刊、可靠新闻源、学术库)微调模型,使其掌握更可靠模式
提示:定期更新微调数据集以跟进最新研究
调整模型参数
降低温度(top-p)值可使输出更确定。虽会限制创造性,但能抑制幻觉倾向。
常见问题
Q1:AI幻觉具体指什么?
A1:当语言模型生成流畅合理但事实错误或完全虚构的内容(如假引文、伪事实、不存在的事件),即发生AI幻觉。
Q2:为何会出现AI幻觉?
A2:源于模型的训练方式:它们优化的是海量多样化数据(含噪声/不完整数据)的下一个词元预测,缺乏内置事实核查机制。
Q3:如何判断AI输出是否为幻觉?
A3:检查不可验证的细节——如通过权威数据库或官方出版物无法核实的论文、引文或数据。接受前请交叉验证名称、日期及来源。
Q4:能完全杜绝AI幻觉吗?
A4:虽无法根除,但可通过具体指令、降低模型温度、结合检索增强生成(RAG)及人工审核大幅减少发生频率。
Q5:哪些最佳实践可减少AI幻觉?
A5:指令工程:要求提供引用来源并指定格式
检索增强:基于实时数据生成内容
生成后验证:使用自动化核查工具与专家评审
模型微调:基于权威精选数据训练
结论
AI幻觉构成重大挑战——但非不可逾越。通过理解其根源,并采用指令工程、检索增强、生成后验证和模型微调等最佳实践,我们既能发挥AI的变革力量,又能保持事实完整性与用户信任。
摘要
<p>探索AI幻觉现象——模型会生成自信但虚假的内容,并学习确保事实完整性与可信度的预防策略。</p>