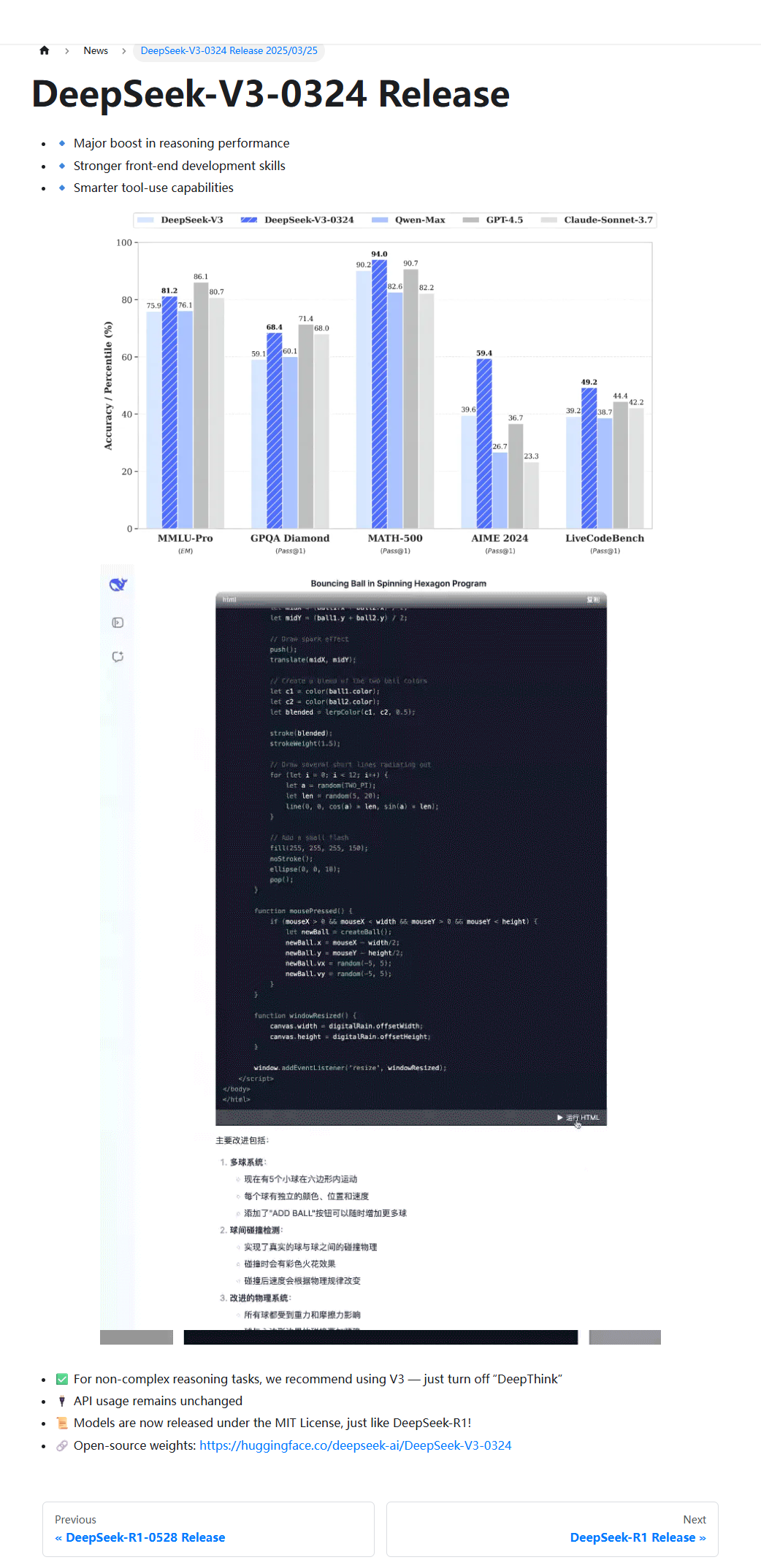
核心特性
- 先进架构
1. 混合专家(MoE)架构,总参数量671亿,每次推理激活37亿参数
2. 多头注意力机制(MLA)
3. DeepSeekMoE架构
- 海量训练
1. 基于14.8万亿高质量多样化语料训练
2. 包含更高比例的数学与编程数据
- 卓越性能
1. 超越Llama 3.1、Qwen 2.5等开源模型
2. 比肩GPT-4o、Claude 3.5 Sonnet等闭源领先模型
- 超长上下文支持
1. 支持128,000 tokens上下文长度
- 功能特性
1. 支持函数调用
2. JSON格式输出
3. 填充式生成(FIM)
- 开源许可
1. 采用MIT开源协议
2. 模型检查点可访问GitHub(DeepSeek-V3代码库)