Hush.
हर बातचीत को साफ़ और स्पष्ट बनाएं
Hush रीयल-टाइम कॉल्स से बैकग्राउंड नॉइज़ और इंटरफ़ेरेंस हटाता है। आपके वॉयस AI एजेंट्स हमेशा साफ़ ऑडियो सुनें।
साप्ताहिक रैंक
▲ #11वोट
183प्लेटफॉर्म
Web / Mobileलॉन्च किया गया
Recently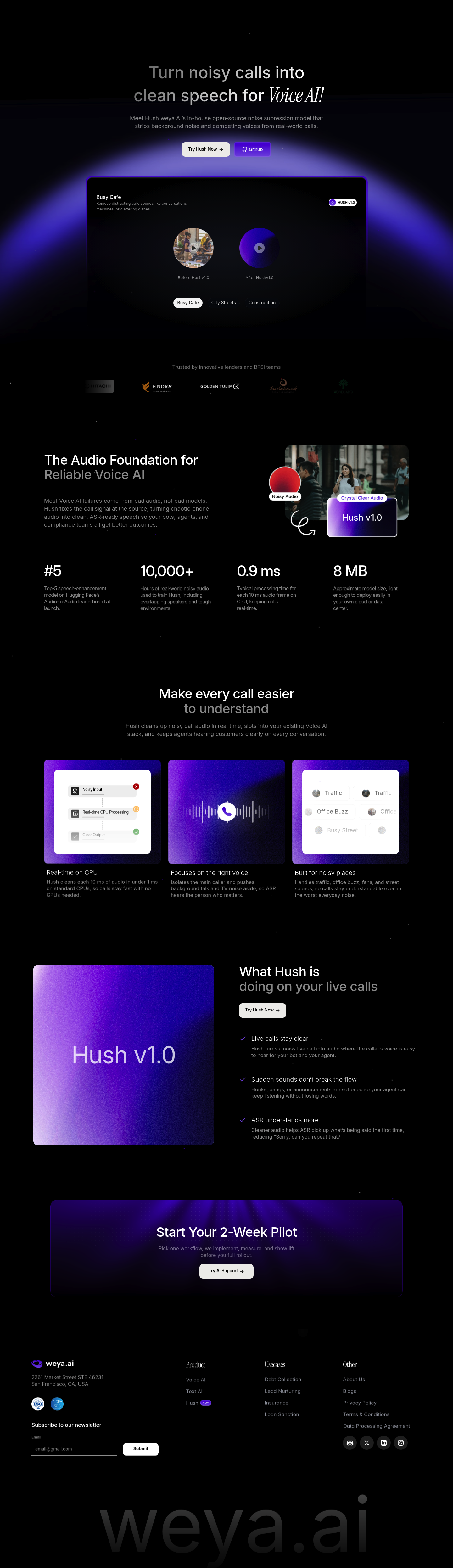
Favorite — quick open from Home.
Hush के बारे में अधिक जानकारी
Hush v1.0 शोर दमन मॉडल
Hush Weya AI का ओपन-सोर्स नॉइज सप्रेशन मॉडल है जो वॉइस AI के लिए रियल-टाइम कॉल्स में पृष्ठभूमि शोर और प्रतिस्पर्धी आवाज़ों को हटाकर साफ़ भाषण प्रदान करता है। यह भारतीय BFSI और लेंडिंग कंपनियों द्वारा विश्वसनीय समाधान के रूप में अपनाया गया है।
मुख्य विशेषताएं
- रियल-टाइम CPU प्रोसेसिंग: मात्र 0.9 मिलीसेकंड में 10 मिलीसेकंड ऑडियो फ्रेम को प्रोसेस करता है, GPU की आवश्यकता के बिना
- कॉम्पैक्ट मॉडल साइज: लगभग 8 MB का हल्का मॉडल जो आसानी से क्लाउड या डेटा सेंटर में डिप्लॉय हो सकता है
- प्रमुख वक्ता पहचान: मुख्य कॉलर की आवाज़ को अलग करता है और पृष्ठभूमि की बातचीत व टीवी शोर को दबा देता है
- वास्तविक दुनिया प्रशिक्षण: 10,000+ घंटे के नॉइज़ी ऑडियो डेटा पर प्रशिक्षित, जिसमें ओवरलैपिंग स्पीकर्स और कठिन वातावरण शामिल हैं
उपयोग के मामले
- कॉल सेंटर ऑपरेशंस: भीड़भाड़ वाले कैफे, सड़क यातायात और निर्माण स्थलों से आने वाली कॉल्स को साफ़ करता है ताकि एजेंट ग्राहकों को स्पष्ट रूप से सुन सकें
- वॉइस AI बॉट्स: ASR सिस्टम के लिए ऑडियो सिग्नल को सुधारता है, जिससे "कृपया दोहराएं" की घटनाएं कम होती हैं और पहली बार में सही समझ बढ़ती है
- कंप्लायंस और मॉनिटरिंग: रेगुलेटरी रिकॉर्डिंग के लिए साफ़ ऑडियो सुनिश्चित करता है, जिससे ऑडिट और गुणवत्ता जांच में सुधार होता है
लक्षित दर्शक
यह उत्पाद BFSI कंपनियों, फintech स्टार्टअप्स, कॉल सेंटर्स और वॉइस AI डेवलपर्स के लिए डिज़ाइन किया गया है जो भारत में शोर भरे वातावरण में भी विश्वसनीय वॉइस इंटरैक्शन चाहते हैं।
आपको यह भी पसंद आ सकता है
सभी विकल्प देखें →