Hush.
Hush eliminates background noise, competing voices & audio interference from real-time calls. Ensure your voice AI agents hear clearly every time.
More About Hush
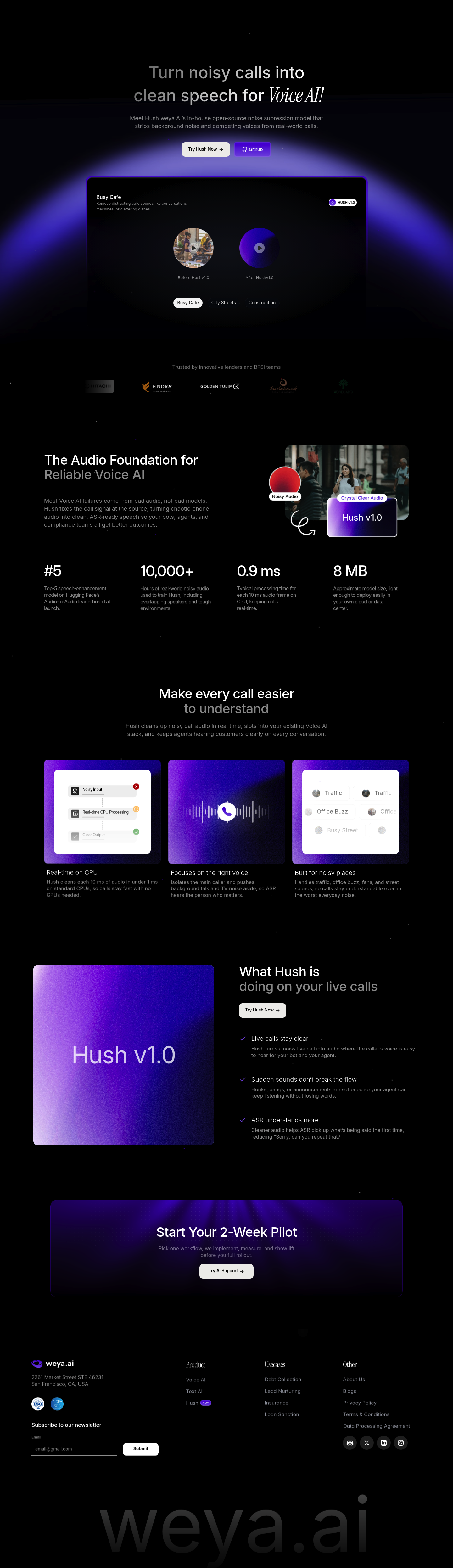
Hush v1.0 Noise Suppression
Hush is an open-source audio enhancement model developed by Weya AI that transforms noisy real-world calls into clean, intelligible speech. Designed specifically for Voice AI applications, it strips away background noise and competing voices at the source, ensuring your automated systems and human agents receive ASR-ready audio that drives better conversation outcomes.
Product Highlights
-
Real-Time CPU Processing: Cleans each 10 ms audio frame in under 1 ms on standard CPUs, eliminating GPU dependency and keeping latency minimal for live calls.
-
Voice Isolation Technology: Intelligently separates the primary speaker from background conversations, TV noise, and overlapping speech, directing focus to the caller who matters.
-
Lightweight Deployment: Compact 8 MB model size enables flexible cloud or on-premise deployment without infrastructure overhead.
-
Rugged Noise Handling: Trained on 10,000+ hours of real-world noisy audio including traffic, construction, cafes, and office environments for reliable performance anywhere.
-
Open-Source Accessibility: Freely available on Hugging Face and GitHub, allowing teams to integrate, customize, and audit the model without vendor lock-in.
Use Cases
-
Voice AI Bot Optimization: Feed cleaner audio into your ASR and NLU pipelines to reduce misrecognition, cut repetition loops, and improve first-call resolution rates.
-
Live Agent Support: Equip human agents with noise-suppressed caller audio so they can focus on solving problems rather than straining to hear through background chaos.
-
Compliance & Quality Assurance: Ensure recorded calls are intelligible for regulatory review and automated analysis, even when captured in challenging acoustic conditions.
-
Field & Mobile Workforce: Enable clear communication for sales, collections, and support teams operating from vehicles, construction sites, or busy public spaces.
Target Audience
Hush serves BFSI organizations, fintech lenders, insurance providers, and any enterprise running high-volume Voice AI operations where audio quality directly impacts customer experience and operational efficiency. Development teams and ML engineers building speech-enabled applications will find particular value in its open architecture and production-ready performance.
You might also like
See all alternatives →