Hush.
让AI智能体在嘈杂环境中也能精准聆听
Hush开源降噪SDK,专为语音AI智能体设计。实时消除背景噪音、人声干扰,确保通话清晰,提升AI识别准确率。
周排行
▲ #11支持数
183适配平台
Web / Mobile上线时间
Recently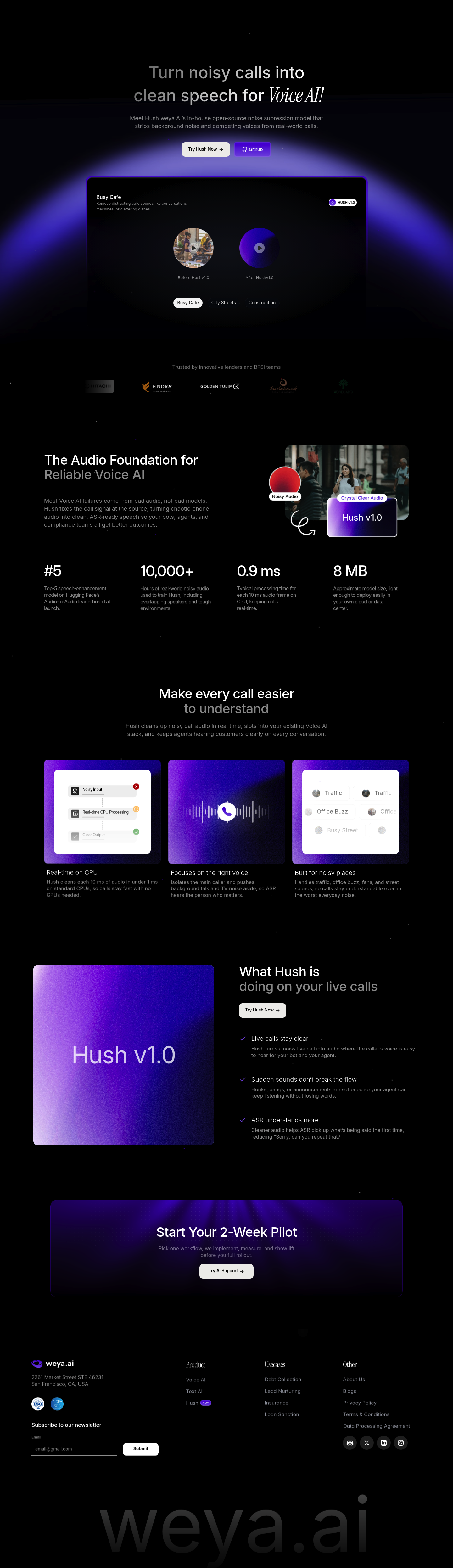
Favorite — quick open from Home.
更多关于 Hush 的信息
Hush v1.0 噪声抑制模型
Hush 是 Weya AI 自主研发的开源语音增强模型,专为实时语音通话场景设计。它能够从复杂的真实环境音频中精准剥离背景噪声、消除重叠人声干扰,将嘈杂通话转化为清晰可懂的纯净语音,为 Voice AI 系统提供可靠的音频基础。
产品亮点
- 开源架构:完全开源的模型权重与代码,支持自由部署与二次开发,无供应商锁定风险
- 实时低延迟:CPU 端每 10 毫秒音频帧处理时间仅 0.9 毫秒,无需 GPU 即可实现实时降噪
- 轻量高效:模型体积仅约 8 MB,可轻松部署于私有云或本地数据中心
- 人声聚焦:智能分离目标说话人,抑制背景对话与电视噪声,提升 ASR 识别准确率
- 复杂场景训练:基于 10,000+ 小时真实世界噪声数据训练,涵盖交通、工地、咖啡厅等高难度环境
应用场景
- 智能客服中心:为 AI 语音机器人与人工坐席提供清晰通话质量,减少"请重复"等交互摩擦,提升首次解决率
- 金融信贷通话:支持贷后催收、贷款审批等 BFSI 场景,确保嘈杂环境下的合规录音质量与语音识别准确性
- 保险理赔沟通:消除街头、车辆等背景干扰,保障远程查勘与理赔沟通的信息完整传递
- 移动办公通话:过滤咖啡厅、机场、共享办公空间等环境的突发噪声,维持专业商务通话体验
目标受众
Hush 主要面向需要部署 Voice AI 系统的金融科技企业、呼叫中心运营商、智能客服解决方案提供商,以及追求通话质量优化的保险、借贷、催收等 BFSI 行业技术团队。
你可能也喜欢
查看所有替代品 →