Hush.
وضوح تام في كل مكالمة مهما كانت الضوضاء حولك
حوّل مكالماتك الصوتية مع Hush. تخلص من الضوضاء والتداخلات في الوقت الفعلي لضمان وضوح صوت وكلمة لعملاء الذكاء الاصطناعي.
الترتيب الأسبوعي
▲ #11الأصوات
183المنصة
Web / Mobileتم الإطلاق
Recently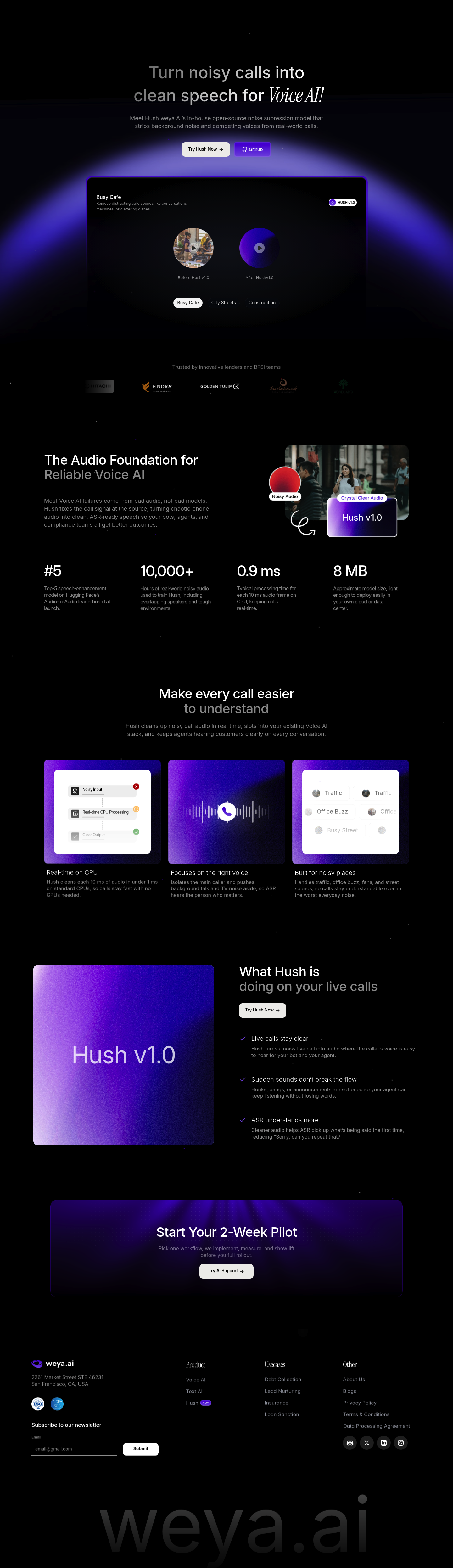
Favorite — quick open from Home.
المزيد عن Hush
Hush v1.0 - نموذج إلغاء الضوضاء مفتوح المصدر
Hush هو نموذج ذكاء اصطناعي متطور من تطوير Weya AI، مصمم لتحويل المكالمات الصوتية المشوشة إلى كلام واضح ونقي. يعمل النموذج على إزالة الضوضاء الخلفية والأصوات المتداخلة في الوقت الفعلي، مما يجعله الأساس المثالي لتطبيقات الذكاء الاصطناعي الصوتي في البيئات الصاخبة.
أبرز مميزات المنتج
- معالجة في الوقت الفعلي: يعالج كل 10 مللي ثانية من الصوت في أقل من 1 مللي ثانية على المعالجات المركزية العادية، دون الحاجة لبطاقات رسومية
- حجم مدمج: يبلغ حجم النموذج تقريباً 8 ميجابايت فقط، مما يسهل نشره في السحابة أو مراكز البيانات
- عزل الصوت الرئيسي: يفصل صوت المتصل الأساسي ويخفف الأصوات المحيطة والمحادثات المتداخلة لتعزيز دقة التعرف التلقائي على الكلام
- تدريب متقدم: تم تدريبه على أكثر من 10,000 ساعة من تسجيلات صوتية واقعية مشوشة، تشمل تداخلات متعددة وبيئات صعبة
حالات الاستخدام
- مراكز الاتصال والخدمة العملاء: تحسين جودة المكالمات الواردة من العملاء في الأماكن العامة مثل المقاهي والشوارع المزدحمة
- القطاع المالي والتأمين: ضمان وضوح التسجيلات الصوتية للامتثال التنظيمي وتحليل المكالمات بدقة عالية
- الروبوتات الصوتية التفاعلية: رفع معدلات فهم الذكاء الاصطناعي للكلام في البيئات ذات الضوضاء العالية
- تطبيقات العمل عن بُعد: تمكين التواصل الواضح للموظفين العاملين من منازلهم أو المساحات المشتركة
الفئة المستهدفة
يستهدف Hush فرق تقنية المعلومات ومديري عمليات مراكز الاتصال في المؤسسات المالية والمصرفية، بالإضافة إلى مطوري تطبيقات الذكاء الاصطناعي الصوتي الذين يسعون لتحسين دقة معالجة الكلام في البيئات الواقعية الصاخبة.
قد يعجبك أيضاً
شاهد كل البدائل →